
1. 동적 계획법(DP)에 대해 설명해주세요.
동적 계획법: 복잡한 문제를 더 작은 하위 문제로 나누어 해결하는 알고리즘 설계 기법
DP를 적용하기 위해서는 2가지 조건을 만족해야 합니다.
첫째, 중복 문제
동일한 작은 문제들이 반복되어야, 부분 문제의 결과를 저장하여 재활용하여 전체의 답을 구할 수 있기 때문입니다.
둘째, 최적 부분 구조
부분 문제의 최적 결과 값을 사용해 전체 문제의 최적 결과를 낼 수 있어야 합니다.
구현 방법
1. Bottom-Up
작은 부분 문제부터 반복문을 통해 문제를 해결하고 값을 저장합니다.(메모이제이션)
2. Top-Down
큰 문제를 재귀 함수를 사용해 작은 부분 문제로 나누고, 중복 계산을 피하기 위해 메모이제이션을 활용합니다.
대표적으로 피보나치 문제, 배낭 문제가 있습니다.
메모이제이션은 한번 계산한 결과를 메모리에 저장해 두었다가 재활용하는 방법입니다.
알고리즘 설계 기법에는 분할 정복, DP, 탐욕적 알고리즘, 백트래킹 등이 있습니다.
2. 재귀 알고리즘과 사용되는 사례에 대해 설명해주세요.
재귀 알고리즘: 자기 자신을 다시 호출하여 작업을 수행하는 알고리즘(재귀 함수를 사용)
재귀 함수: 자신을 다시 호출하여 작업을 수행, 매개변수가 달라질 뿐 같은 작업을 함
재귀 함수 요건: 종료 조건(재귀적 호출에서 빠져나오는 탈출 조건), 재귀 호출
사용되는 사례
하노이 탑 같은 피보나치 수열, 팩토리얼, 이분 탐색, DFS 등의 재귀적 수행이 필요한 문제를 푸는데 활용됨
3. 최단거리 알고리즘에 대해 설명해주세요.
최단 거리 알고리즘: 그래프 상에서 노드 간의 탐색 비용을 최소화하는 알고리즘, 네비게이션에서 활용됨
종류는 BFS, 다익스트라, 벨만 포드, 플로이드 워셜 알고리즘이 있습니다.
가중치가 없다면 BFS를 사용해서 구할 수 있지만, 있다면 불가능합니다.
다익스트라는 음의 가중치가 있다면 활용 불가능합니다. 가중 그래프에서 간선 가중치의 합이 최소가 되는 경로를 찾기 때문입니다.(특정 한 노드에서 다른 모든 노드)
벨만 포드는 다익스트라 한계 보완(음의 가중치), 그렇지만 변경사항이 있을 때까지 계속 탐색을 진행하기때문에 시간이 오래 걸리고, 음의 사이클이 발생하는 경우에는 사용 불가능합니다.
플로이드 워셜은 모든 정점에서 모든 정점으로 가는 최단 거리를 구합니다.
인접행렬을 만들고(무한대로 초기화), 경유지를 기준으로 해당 경유지를 거쳐가는게 빠르다면 갱신합니다.
4. 빅오표기법에 대해 설명해주세요. (특징, 성능 순서 등)
원소가 N개일때 알고리즘에 몇 단계가 필요할까
빅오표기법은 알고리즘의 효율성을 표기해주는 표기법 중 하나입니다.
특징은 최악의 실행 시간을 표기한다는 것 입니다. 또한 시간복잡도에 영향이 적은 것은 배제하고 표기합니다.(상수, 계수, 최고차항만 표기)

성능 순서: O(1) < O(log N) < O(N) < O(N log N) < O(N^2) < O(2^N)
O(1)은 N이 무슨값이든 단계수가 일정하다는 것입니다.
5. 선택정렬에 대해 설명해주세요.
배열의 가장 작은 값의 인덱스를 찾고, 그 값을 앞에서부터 채워나가면서 정렬하는 방식
시간복잡도는 O(N^2)(비교+swap)
5 3 1 2
1 3 5 2
1 2 5 3
1 2 3 5
6. 이진탐색에 대해 설명해주세요.
이진탐색은 정렬되어 있는 리스트에서 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하는 방법입니다.
특정 데이터를 찾는 경우: 가운데값과 비교하여 타겟값보다 작으면 끝점 이동, 크다면 시작점 이동으로 범위 좁히기
응용: 원하는 값이 몇번 등장했는지(길이, 갯수)
가장 처음 등장하는 부분과 가장 마지막 부분을 찾아서 계산
파라메트릭 서치: 조건을 만족하는 최소 or 최댓값을 찾는 문제
7. 스위핑 알고리즘에 대해 설명해주세요.
특정 기준에 따라 정렬된 순서대로 문제를 처리하는 방법으로
이러한 라인스위핑 알고리즘은 좌표 문제에 많이 사용되며,
일정 좌표, 축기준 정렬 한 뒤 일정 시점의 좌우 가장 가까운 두 점사이의 거리보다 멀리떨어진 점은 조사하지 않는 가지치기를 통해 시간복잡도는 O(NlogN)입니다.
8. KMP 알고리즘에 대해 설명해주세요.
KMP 알고리즘은 문자열 매칭 알고리즘으로 글 안에서 특정 문자열을 찾는 알고리즘입니다.
기존의 단순 비교 문자열 매칭 알고리즘의 반복 연산을 줄여 모든 경우를 비교하지 않고 문자열을 찾을 수 있습니다.
접두사와 접미사를 구하여 접두사와 접미사가 일치하는 경우에 점프하기 때문에 중복을 피할 수 있습니다.
9. 위상 정렬에 대해 설명해주세요.
각 정점들이 가지는 위상(다른 정점과의 관계, 간선)에 따라서 그래프를 구성하는 정점들을 순서대로 정렬하는 정렬 기법입니다.
이러한 위상 정렬은 주로 순서가 정해져 있는 작업을 차례대로 수행해야 할 때 사용합니다.
또한, 방향성 비순환 그래프라는 특징을 갖고 있습니다.
위상 정렬의 순서
큐 or 재귀로 구현이 가능(보통 큐를 사용해서 많이 구현)
1. 그래프의 각 노드들의 진입 차수 테이블 생성 및 진입 차수 계산
2. 진입 차수가 0인 노드 큐에 넣기(어떤 노드를 먼저 시작하는 것은 관계 없음)
3. 큐에서 노드를 하나 꺼낸 후 꺼낸 노드와 간선으로 연결된 노드들의 진입 차수 감소
(진입 차수 테이블 갱신)
4. 진입 차수 테이블을 갱신 후 진입 차수의 값이 0인 노드가 있다면 큐에 넣기
(없으면 넘어감)
5. 3과 4번의 순서를 큐에 더 이상 아무것도 없을 때 까지 반복
위의 순서로 위상 정렬은 수행되며, 모든 순서가 끝났는데도
진입 차수가 0이 아닌 노드가 있다면 그래프는 순환한다고 보면 됨
10. BFS와 DFS에 대해 설명해주세요.
그래프 탐색 방법의 종류
BFS(너비 우선 탐색)
- 현재 정점에 연결된 가까운 점들부터 탐색
- 자료구조 큐 활용
DFS(깊이 우선 탐색)
- 현재 정점에서 갈 수 있는 점들까지 들어가면서 탐색
- 스택, 재귀
어떨 때 쓰면 유리할까?
경로의 특징을 저장해둬야 된다면 DFS(매개변수 활용+메모이제이션)
최단 거리를 구해야 한다면 BFS(너비 우선 탐색일 결루 먼저 찾아지는 해답이 곧 최단 거리임)
11. Prim과 Kruskal 알고리즘에 대해 설명해주세요.
프림과 크루스칼 둘다 MST의 종류입니다.
MST는 최소 스패닝 트리로 그래프에서 그래프의 모든 정점을 연결하되,
사이클이 존재하지 않도록 모든 정점을 간선으로 연결하고, 간선의 가중치 합을 최소로 갖는 트리입니다.
프림은 시작 정점을 기준으로 가장 작은 간선과 연결된 정점을 선택하여 모든 노드를 연결합니다.
1. 임의의 간선 선택
2. 현 정점으로부터 가장 낮은 가중치를 갖는 정점 선택
3. 모든 간선에 대해 반복
크루스칼은 모든 간선에 대해 가장 가중치가 작은 간선부터 연결합니다.
유니온 파인드 자료구조를 기반으로 생성하며, 간선의 가중치의 합이 최솟값이 되도록 모든 노드를 연결합니다.
1. 간선 데이터를 오름차순 정렬
2. 간선을 확인하며 현 간선이 사이클을 발생시키는지 확인
- 발생시키지 않으면 MST에 포함
3. 모든 간선에 대해 반복
12. 알고 있는 정렬 알고리즘에 대해 설명해주시고 비교해서 어떤 차이가 있는지 설명해주세요.
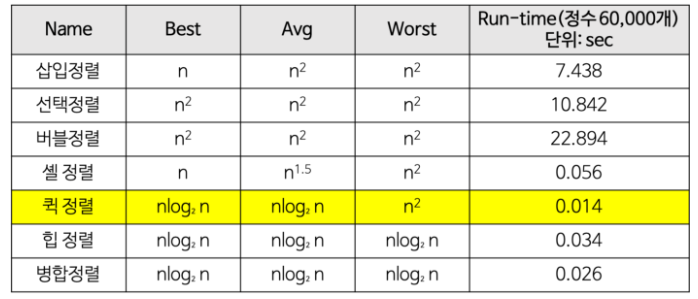
삽입정렬: 앞에서부터 차례대로 이미 정렬된 부분과 비교하여 교환하는 방식
선택정렬: 배열의 가장 작은 값의 인덱스를 찾고, 그 값을 앞에서부터 채워나가면서 정렬하는 방식
버블정렬: 인접한 원소끼리 비교하여 교환하는 방식
퀵 정렬: 기준을 정하고 중심축보다 작은 요소를 왼쪽으로, 큰 요소를 오른쪽으로 보내는 작업을 여러 차례 반복하여 정렬하는 방식
'CS' 카테고리의 다른 글
| [CS] Spring에서 Bean 등록하는 방법 (0) | 2024.04.29 |
|---|---|
| [CS 스터디] Spring (0) | 2024.04.29 |
| [CS 스터디] Java(자바) (0) | 2024.04.17 |
| [CS 스터디] 자료구조(Data Struture) (0) | 2024.03.26 |
| [CS 스터디] 데이터베이스(DB) (1) | 2024.03.20 |